‘Twoje dane ukrywają przed Tobą prawdę’, czyli dlaczego wiedza o próbkowaniu danych w GA4 jest taka ważna
Analityka, Growth, StartupyWbrew pozorom tytuł mojego wpisu nie jest żadnym clickbaitem, ani też wyolbrzymieniem. Nie jest też czymś nowym, bo sampling danych był już wprowadzony w starej wersji GA (Universal Analytics) i to z większymi restrykcjami (choć tutaj nie jestem do końca przekonany, o czym opowiem później).
Jednak żyjemy obecnie w takich czasach, gdzie każda informacja, każda dana o Twoim biznesie może być na wagę złota:
- czy ta reklama dowozi mi jakościowe leady?
- czy moi użytkownicy korzystają z funkcji, którą ostatnio wydaliśmy, czy trzeba ich trochę ‘szturchnąć kijem’?
- kto najczęściej korzysta z funkcji X: grupa docelowa A czy B?
- i tak dalej…
I te odpowiedzi powinniśmy potencjalnie uzyskać właśnie z narzędzia pokroju Google Analytics 4. I tutaj właśnie pojawia się aspekt próbkowania danych, który może skutecznie rzucić nam kłodę pod nogi podczas szukania odpowiedzi na nurtujące nas pytania.
Ale zasadniczo, czym właściwie ono jest?
W skrócie
“Badanie zostało przeprowadzone na 1000 ankietowanych”
To słynne zdanie jest koncepcyjnie identycznym zjawiskiem jak próbkowanie danych w GA4 – analizujemy podzbiór (próbkę) zamiast całej populacji, aby wyciągnąć wnioski z całości.
Badania ankietowe: Zamiast pytać wszystkich 38 milionów Polaków o ich preferencje polityczne, badamy 1000 osób i ekstrapolujemy wyniki na całą populację.
Sampling w GA4: Zamiast analizować wszystkie 50 milionów zdarzeń z trzech miesięcy, Google Analytics analizuje np. 20% z nich (10 milionów) i ekstrapoluje wyniki, aby oszacować metryki dla całego zbioru.
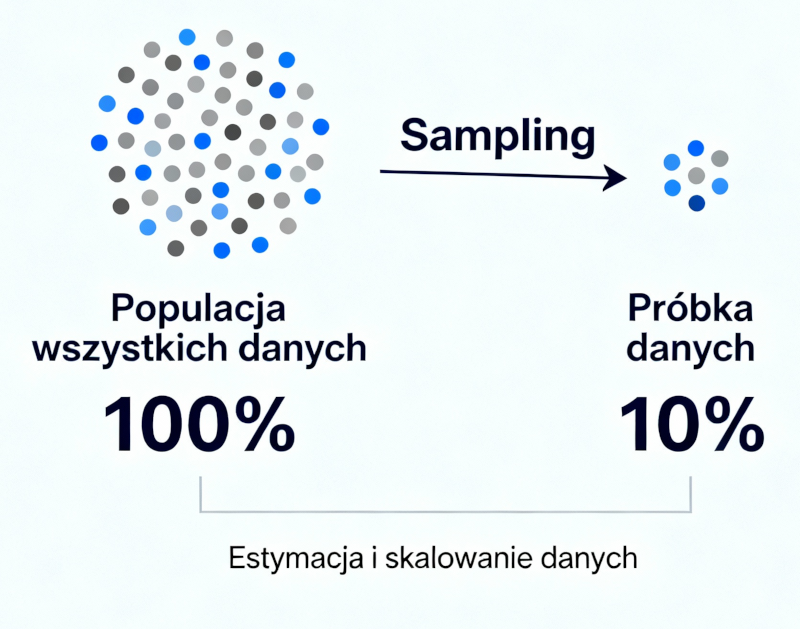
Prosta grafika pokazująca koncept samplingu danych, czyli estymacji na podstawie wybranego podzbioru
W obu przypadkach cel mamy identyczny: uzyskanie wystarczająco dokładnych wyników przy znacznie mniejszym nakładzie zasobów obliczeniowych (GA4) lub finansowych/czasowych (ankiety).
Jakby nie patrzeć oczekujemy otrzymania raportu w parę sekund na podstawie tysięcy a czasem i milionów pojedynczych informacji zebranych w naszym projekcie poprzez GA4. A takich firm jak my globalnie jest setki tysięcy. To wymaga dużo zasobów, a GA4 jest zasadniczo darmowe.
No dobrze, tylko po co Ci ta cała wiedza?
Otóż próbkowanie danych wpływa na dokładność raportów – metryki i wyniki mogą być jedynie estymacją, a nie precyzyjnym odzwierciedleniem rzeczywistości, co może nas prowadzić do błędnych wniosków i działań.
Przykładowo, według danych w poprzednich 60 dniach pozyskaliśmy 20 leadów na rozmowę z działem Sprzedaży, z czego 12 z kampanii na LinkedIn, 6 z kampanii w Google, a pozostałe 2 z ruchu bezpośredniego (Direct).
Ucieszeni tym faktem zwiększyliśmy budżet w kanale LinkedIn, bo jakby nie patrzeć kampania dowozi leady.
Po pewnym czasie okazało się jednak, że dane były próbkowane i Google Analytics źle estymował w większym przedziale czasowym liczbę leadów – po głębszym sprawdzeniu wyszło, że leadów z kampanii w LinkedIn było ‘jedynie’ 7, za to 10 było z kampanii w Google, a 3 z ruchu Direct.
Tym samym zwiększyliśmy budżet tam, gdzie nie przynosiło to tak dużego efektu.
Będą znaki
Wykrywanie tego, że mamy próbkę danych zamiast całego zbioru jest dosyć proste.
W przypadku raportów standardowych (te podstawowe, domyślnie stworzone w GA4) nie występuje próbkowanie, czyli raporty te zawsze odzwierciedlają 100% posiadanych danych.
Potwierdza to zielony ‘ptaszek’ przy danym raporcie:

W raportach standardowych nie występuje próbkowanie danych
Natomiast wiemy, że raporty standardowe dają tylko powierzchowny wgląd w to, co się dzieje w naszym biznesie i potrzebujemy stworzyć własne raporty, które będą dostosowane do naszych potrzeb.
Jest to szczególnie ważne dla startupów, gdzie samo wdrożenie analityki jest nieszablonowe (czasem mocno wykraczające poza dokumentację Google), a co za tym idzie również i analizowanie śledzonych zdarzeń.
Własne raporty tworzymy oczywiście poprzez moduł Explore (Eksploruj w wersji pl) i to tam głównie występuje próbkowanie danych.
I o ile sam panel do tworzenia niestandardowych raportów (Eksploracji) może być na starcie mocno przytłaczający, o tyle wykrycie samplingu jest banalnie proste:
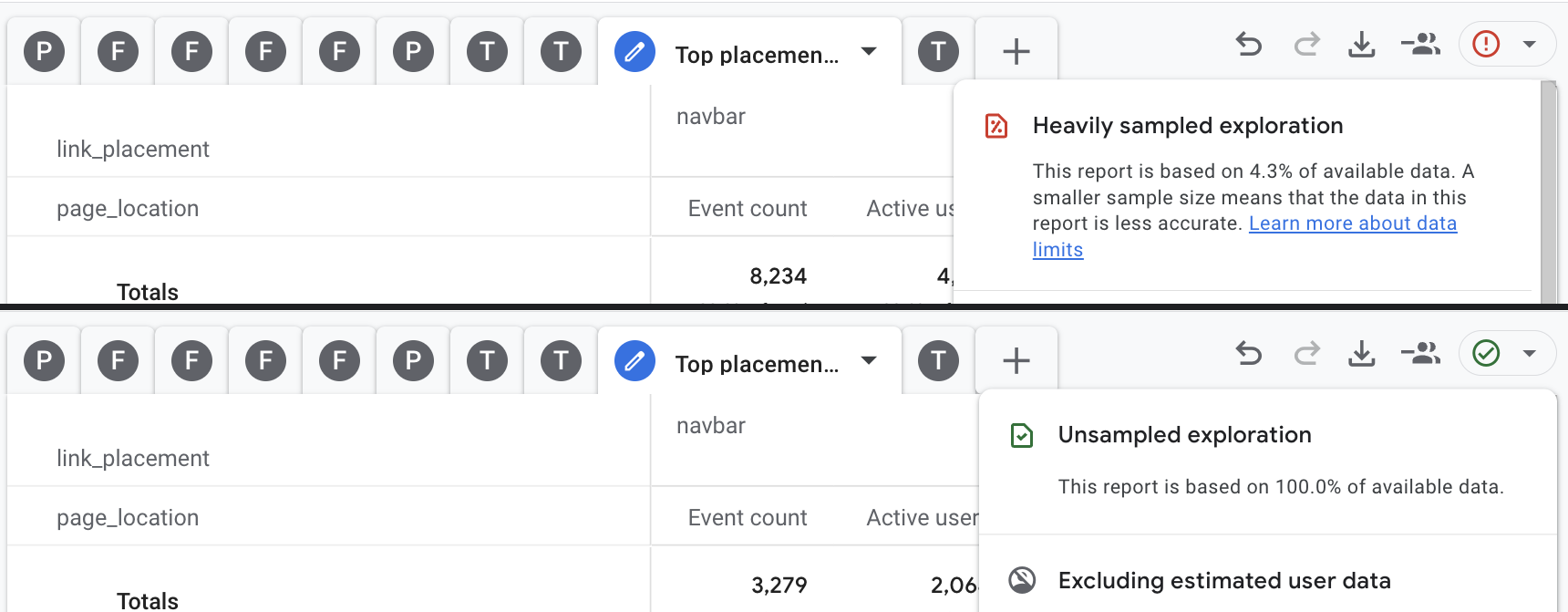
Przykład samplowania danych tego samego raportu niestandardowego w przypadku 12 ostatnich miesięcy vs ostatnie 90 dni, gdzie próbkowanie danych nie występuje
Wiemy już jak wykryć sampling danych w GA4, czas na zrozumienie, co dokładnie może go powodować:
- użycie dużego zakresu czasu, np. w sytuacji kiedy chcesz badać sezonowość lub robić analizę rok do roku,
- stosowanie wielu miar, wymiarów oraz złożonych filtrów, np. kiedy robimy głęboki research odnośnie konkretnych kampanii,
- przekroczenie domyślnego limitu zdarzeń (10 mln zdarzeń), zazwyczaj w przypadku dużego przedziału czasowego, ale i też w przypadku dużej ilości ogólnych danych, np. najczęściej odwiedzane strony w ostatnich 3 miesiącach w dużym portalu newsowym.
Zatrzymajmy się na chwilę przy limitach.
Jak już wspomniałem na wstępie, w starej wersji Google Analytics mieliśmy ponoć mniejsze limity, dokładnie to 500 000 sesji dla używanego okresu danych.
W przypadku GA4 mamy limit 10 mln zdarzeń, czyli liczbowo faktycznie lepiej (10 mln jest większe od 500 tys. – oczywistość), ale porównujemy jabłka do gruszek, bo sesje to nie to samo co zdarzenia.
Nie wchodząc teraz zbytnio w szczegóły co jest czym, zmierzam do tego, że przy bardzo zaangażowanych użytkownikach, limit 10 mln zdarzeń szybciej ‘wyczerpiemy’ niż to, że w danym przedziale czasowym będziemy mieć 500 tysięcy sesji użytkowników.
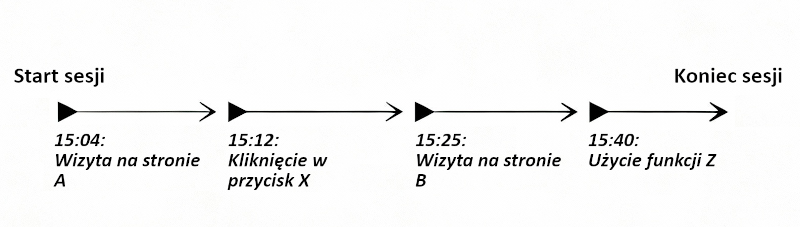
1 sesja zawiera wiele zdarzeń – im użytkownik jest bardziej zaangażowany, tym więcej zdarzeń będzie do niego przypisanych
Jest to o tyle ważne właśnie w przypadku startupów i tego, że śledzenie wykorzystania konkretnych funkcji w SaaS czy marketplace zużywa więcej zdarzeń (eventów), a co za tym idzie, zamiast cieszyć się 100% dokładnością danych, mamy próbkowane raporty.
Więc, czy jest lepiej? To zależy 🙂
Jak żyć?
Wiemy już, że sampling w GA4 przeszkadza, i w robieniu analiz długoterminowych, i tych głębokich.
Sposobów na radzenie sobie z próbkowaniem danych jest kilka:
- Zmniejszenie przedziału czasowego raportu – wiem, wiem, nie można nazwać to pełnoprawnym rozwiązaniem, bo robiąc analizę z ostatnich 12 miesięcy czeka Cię każdorazowe szukanie przedziału, w którym nie masz próbkowania danych, a później zsumowanie tego wszystkiego i dopiero wyciąganie wniosków, więc generalnie #orkanaugorze
- Uproszczenie raportu – nie zawsze jest możliwe, szczególnie przy głębokiej analizie, ale czasem faktycznie niepotrzebnie wrzucimy zbyt dużo wymiarów, metryk lub segmentów w Eksploracji
- Eksport danych do BigQuery – BQ pełni funkcję hurtowni danych, czyli składowiska, gdzie możemy przesyłać dane z wielu miejsc, a następnie łączyć i obrabiać je; zaletą eksportu danych z GA4 do BigQuery jest to, że w ten sposób przesyłamy tzw. surowe dane, czyli wszystko co śledzimy z poziomu GA4, ale bez samplingu; minusem jednak jest to, że wymaga znajomości języka zapytań SQL oraz generalnie większej wiedzy technicznej, aby stworzyć sobie raporty na podstawie surowych danych
- Migracja lub wdrożenie innego rozwiązania, które nie wymusza na nas próbkowania danych – generalnie jest to czasochłonne rozwiązanie, gdyż wymaga opracowania wdrożenia analityki w produkt lub stronę od nowa, ale czasem będzie to najlepsze rozwiązanie, np. Mixpanel, Amplitude czy PostHog dają pełną kontrolę nad próbkowaniem danych

Szybkie porównanie GA4 vs Mixpanel, Amplitude i PostHog w kontekście próbkowania danych
Czyli całość można sprowadzić do 3 sytuacji:
- zaciskamy zęby, a od czasu do czasu ‘rzucamy mięsem’ korzystając z GA4
- stawiamy BigQuery i przesyłamy tam dane, po czym tworzymy sobie własne raporty w oparciu o SQL
- wdrażamy analitykę marketingową lub produktową poprzez narzędzia pokroju Mixpanel, Amplitude lub PostHog, które dają nam kontrolę nad tym, kiedy chcemy użyć próbkowania, a kiedy jest nam to nie na rękę.
Ciekawostka:
Tworzenie raportów w Looker Studio, gdzie źródłem danych jest GA4, nie spowoduje, że pozbędziemy się próbkowania.Nadal będziemy go mieć, przy czym nie będziemy widzieć żadnego znaku typu ptaszek/wykrzyknik, który by na to wskazywał, bo tam interfejs nie przewiduje czegoś takiego jak sampling danych, ale źródło danych już owszem.
Wiedza to potęgi klucz – podsumowanie
Ci, którzy oglądali 4 część przygód Indiany Jonesa, pamiętają zapewne tytułową Kryształową Czaszkę – artefakt dający nieograniczoną moc wiedzy. Pułkownik Spalko nie zdołała jednak jej udźwignąć i dosłownie spłonęła od nadmiaru informacji przekraczającej ludzkie możliwości.
Na szczęście w świecie danych taki los nam nie grozi. Znacznie większym zagrożeniem jest ich brak – gdy nie widzisz w swoich raportach części realnych użytkowników, klientów lub leadów, Twoje decyzje stają się ryzykowne i mogą prowadzić na manowce.
Świadomość, czym jest próbkowanie danych w GA4 i jak sobie z nim radzić, to krok w stronę bardziej wiarygodnych analiz, lepszego zrozumienia klientów i – w efekcie – sukcesu Twojego produktu lub usługi.
